SysGit and Security: Low-Touch by Design
Most systems modeling tools ask you to trust them with your data. SysGit doesn't want it.
Most systems modeling tools ask you to trust them with your data. SysGit doesn't want it.
That sounds like a throwaway marketing line, so let me explain what it actually means in practice and why it matters if you're operating in environments where data control isn't optional.
The Problem with 'Deploy Our Database in Your Enclave'
Traditional MBSE tools store your models in proprietary databases. When your security team asks where sensitive model data lives, the answer involves that vendor's backend infrastructure. When compliance auditors want to understand data flows, you're mapping out a third-party application stack you don't fully control.
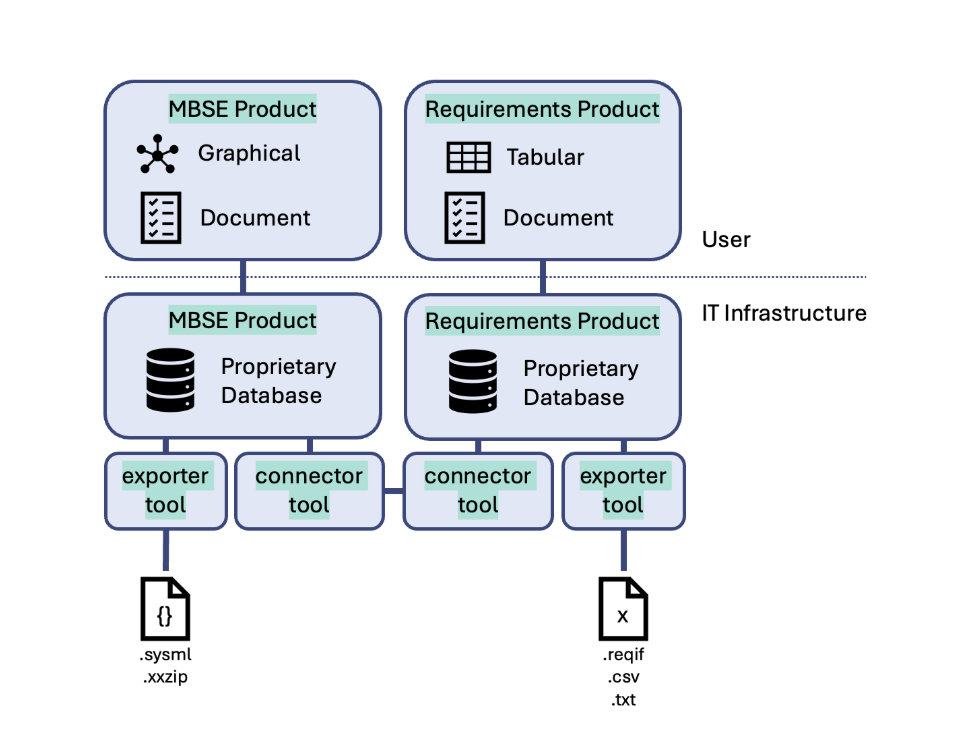
The standard pitch from these vendors goes something like: "We'll deploy our database inside your security boundary." And sure, that works. But now you're operating and maintaining another database. You need DBAs or at least someone who understands that vendor's specific storage layer. You need to back it up, patch it, monitor it, and include it in your ATO boundary. Your security team has to assess and approve yet another system that handles controlled data.
All of this for what is, fundamentally, a modeling tool.
What 'Post-Cloud' Actually Means
SysGit changes this. You don’t need a new database. Our platform doesn’t even handle your data. With SysGit, security is baked in, not bolted on. We’re changing not just what you can do with an MBSE tool, but how you deploy it. We describe SysGit's architecture as "post-cloud," which admittedly sounds like a buzzword. Here's the substance behind it.
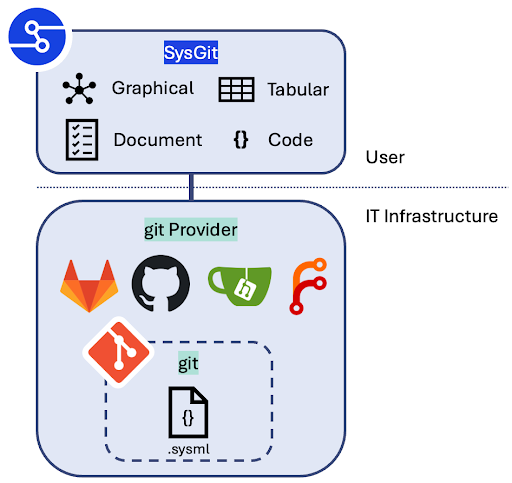
SysGit doesn’t require a stack of brittle tooling. It’s just Git and open standards. SysGit ships as either a desktop application or a self-hosted package. In both cases, it functions as a client application. It does not store your model data. It does not transmit your model data to our servers. There is no SysGit backend that persists anything. Your .sysml files live in Git, and that's it.
Your Git provider (GitHub, GitLab, Gitea, Forgejo) is the entire persistence layer. SysGit reads from it and writes to it. Nothing in between.
This wasn't an accident or a cost-saving measure. We built it this way because our customers have already spent enormous effort deploying and securing their Git infrastructure to whatever standard their environment requires. They have teams who know how to operate these platforms. They have existing security assessments, monitoring, and access controls already in place.
Why would we ask them to do all of that again for a separate system?
Your Existing Security Investment, Unchanged
With SysGit, the math on security changes. One new platform doesn’t require countless new tools, policies, and architecture to secure. This is where the architecture pays off concretely.
Authentication is whatever your Git provider already uses. If you've deployed SSO through your GitLab instance, SysGit uses that. No separate identity provider configuration. No additional credential stores.
Access control maps directly to repository permissions. Want to restrict who can modify the thermal subsystem model? That's repo-level or branch-level access control in Git. Your existing RBAC policies apply without modification. The same permission model your software teams already understand and your security team has already approved.
Audit logging is Git's commit history. Every change to every model element is a commit with an author, timestamp, and diff. This isn't a feature we built. It's an inherent property of storing models as text files in version-controlled repositories.
To be clear, none of this required us to build new authentication, authorization, or audit logging systems. Your organization already has them. We just don't get in the way.
What This Means for Compliance
If you're working in defense, aerospace, or any domain where ITAR applies, data residency is non-negotiable. Your controlled technical data cannot leave approved boundaries.
As a client application, SysGit simplifies this dramatically. The tool itself doesn't disseminate controlled information because it doesn't store or relay it anywhere. Your data stays in your Git infrastructure, which sits inside whatever security boundary you've already established and gotten approved.
For ATO purposes, the footprint you're assessing is a client application, not a client-server system with a proprietary database, API layer, and all the associated attack surface. The difference in assessment scope is significant. Anyone who's been through an ATO process knows that a smaller boundary means fewer controls to document, fewer components to scan, and a faster path to authorization.
CMMC is, to put it diplomatically, still sorting itself out. But regardless of where those requirements land, the fundamentals don't change: you need to demonstrate control over where CUI lives and who can access it. When your modeling data lives exclusively in infrastructure you already control and have assessed, that story is straightforward to tell.
The Git Security Model Is Battle-Tested
There's a deeper point here that goes beyond convenience.
Git's integrity model is cryptographic. Every commit is a SHA hash that depends on the content, the author, the timestamp, and the parent commit. Tampering with history is detectable. Signed commits add another layer of verification on top of that.
These aren't properties we invented for systems modeling. They're properties that the entire software industry has relied on for years, that security researchers have scrutinized extensively, and that your organization's security team almost certainly already trusts for source code. Your system models now get the same protections, automatically.
Low Touch by Design
We keep coming back to this phrase internally: "low touch." It reflects a belief that a modeling tool shouldn't require its own infrastructure team.
Your IT staff already knows how to manage Git. Your security team already has Git in their assessment boundary. Your developers already know Git workflows. Your access control policies already cover Git repositories.
SysGit plugs into all of that. It doesn't replace any of it, and it doesn't add a parallel stack beside it.
For organizations where security isn't a checkbox but an operational constraint that shapes every tool decision, that's the architecture that makes sense. Not because we say so, but because it means one fewer system to secure, one fewer database to protect, and one fewer vendor to trust with your data.
We'd rather build a great modeling tool than ask you to trust us with your models.