No Go-betweens, No Proxy Servers, Just SysML v2 in Git

We made a diagram of how easy it is to integrate your SysML v2 architecture models and requirements into your Git and DevOps infrastructure when using SysGit. It’s short.
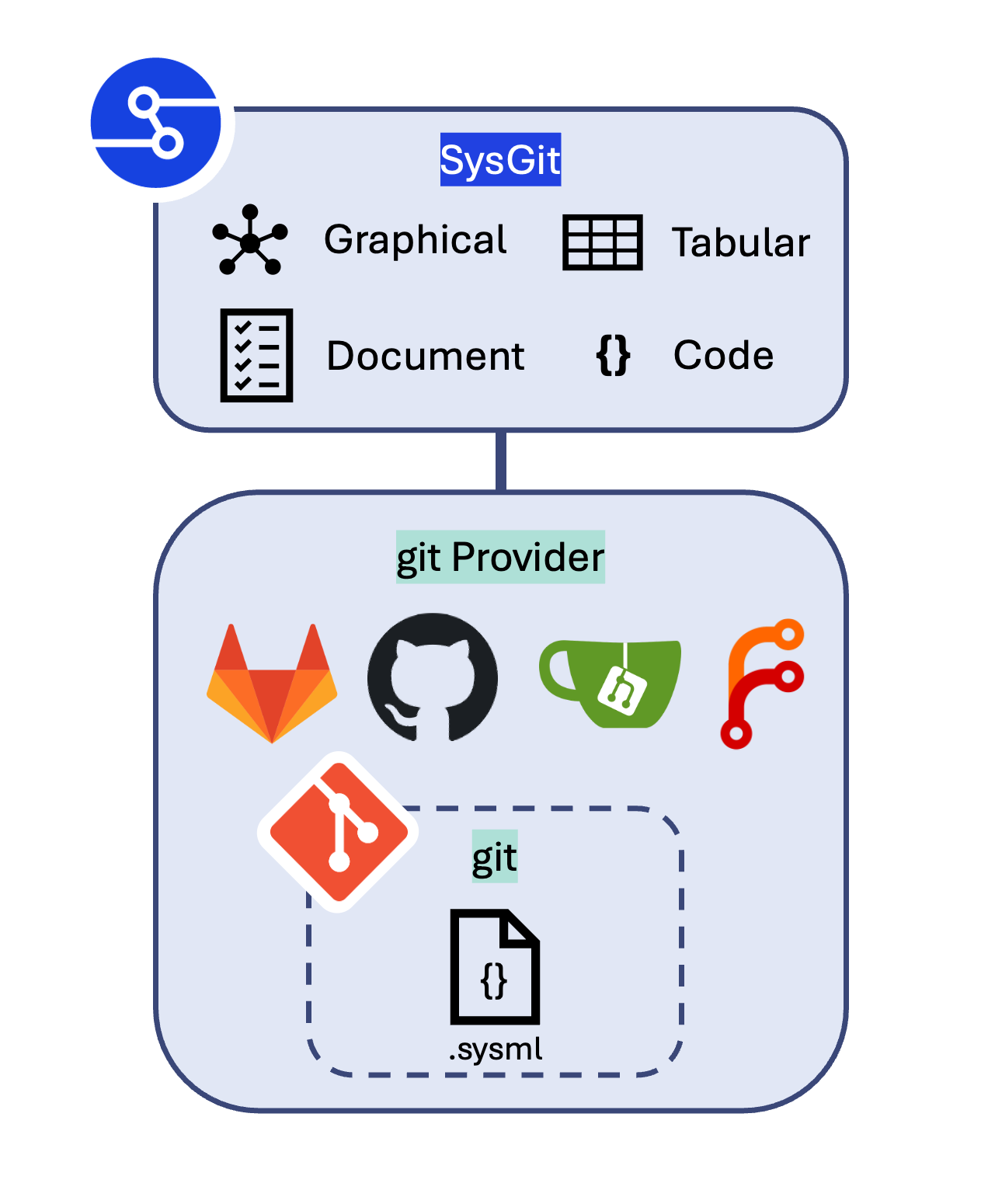
That's it. That's the whole integration. No proxy servers, no man-in-the-middle conversion services, no pipeline that goes model -> export -> transformation -> sync server -> GitLab. The secret is, there practically is no integration. Your SysML v2 model is in GitLab the moment you save it. GitLab CI/CD can see it immediately, because it's just a file in a repo.
If you've ever tried to plumb a traditional MBSE tool into a CI/CD pipeline, that simplicity probably sounds suspicious. Traditional workflows typically involve exporting to an intermediate format, standing up a conversion service, writing custom scripts to push the result somewhere your pipeline can actually reach, and hoping nothing breaks when the tool vendor ships an update. Here’s an example of how that pipeline might work in another tool.
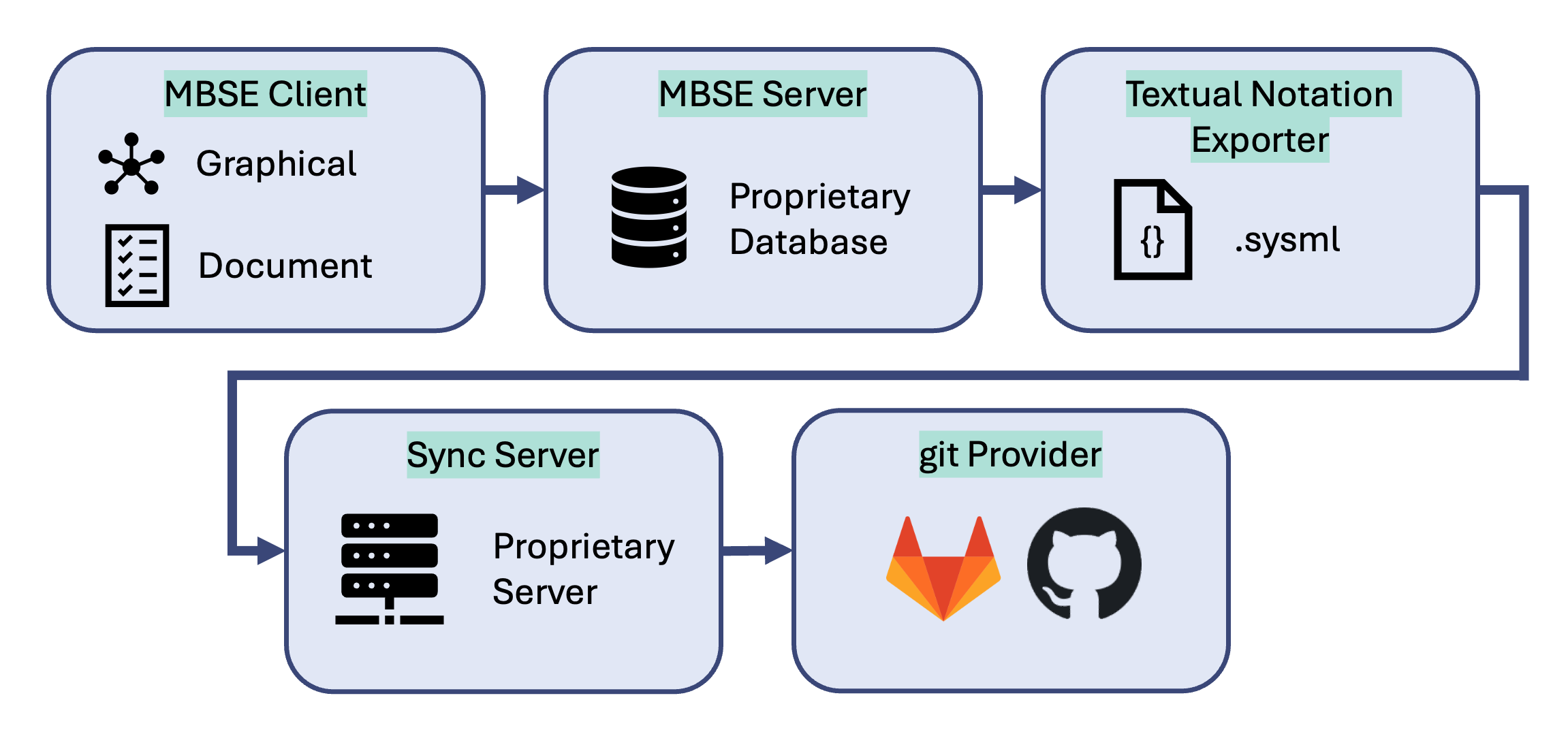
A lot of infrastructure to maintain to solve a problem that shouldn't exist. How much more infrastructure is required to sync data from GitLab back into your MBSE Model?
SysGit skips all of that. Your model is a Git repository. A .sysml file is the same as any other source file. GitLab doesn't know or care that it describes a systems model rather than a software module.
What a SysGit Pipeline Actually Looks Like
When an engineer commits a change to a .sysml file, whether they made that change through the textual editor or by dragging a connection in the graphical view, GitLab sees a standard Git push. From there, your .gitlab-ci.yml takes over just like it would for any other codebase.
A typical pipeline might validate the model, kick off automated analyses, run consistency checks against a defined set of requirements, generate a report or artifact, and flag any coverage gaps. All triggered automatically on commit. All running against the actual model files, not an exported snapshot.
No proxy service sitting in the middle translating between the tool's internal format and something the pipeline can consume. No manual export step that someone forgets to run. The commit is the trigger, and the files in the repo are the inputs.
Traditional MBSE tools store models in proprietary databases or binary formats. Getting data out of them in a form that automation can work with requires either vendor-provided APIs (with their own learning curve and licensing considerations) or export workflows that are inherently manual and lossy.
The consequence is that CI/CD integration for those tools is always a second-class citizen. You're building around the tool rather than with it.
Because SysGit models are plain text files in a Git repository, every standard DevOps tool works with them natively. Static analysis tools, custom validation scripts, document generation, requirements traceability reports… if it can read a file, it can operate on your model. No proxy service required.
Parallel Development Without the Coordination Tax
This also changes how teams collaborate on models during active development. With Git branching, engineers can work on separate aspects of the same model simultaneously. One can refine the thermal interfaces, another can update the requirements to the latest specification while a third is wiring together a complicated analysis that can run automatically on each commit. All can happen simultaneously without locking each other out or manually coordinating who "has" the model.
When they're ready to merge, they get a standard textual diff, or you can use SysGit’s built-in graphical diff computed from the same files. GitLab's merge request workflow handles the review process the same way it would for code. Comments, approvals, pipeline checks on the feature branch before merge, all of it works out of the box.
That's not something you retrofit into an MBSE tool. It requires the model to actually live in Git.
If you're comparing tools and CI/CD integration is on your checklist, the question worth asking isn't "does this tool have a CI/CD integration?" It's "what does that integration actually require to maintain and scale?"
A proxy service or export workflow that works today can break when the tool updates, when your pipeline runner changes, or when someone on the team who built the integration leaves. SysGit's integration isn't a feature bolted on; it's a direct consequence of SysGit building SysML v2 modeling directly into Git.
Your pipeline treats model commits like code commits because, structurally, they are.